Insight
A Guide to Healthcare Data Governance and Getting Started
Ready to unlock your data’s full potential? Learn how effective healthcare data governance can improve decision-making, operational efficiency, and more.

The zero-copy data lake is a new data paradigm, offering faster, more reliable feature delivery and a simplified structure for data consumption, production, and storage.
As healthcare organizations’ data and applications grow rapidly, so does healthcare’s need for a scalable, sustainable data ecosystem. Put simply: healthcare produces a massive amount of information, and users need a central place to store it safely and access it easily. Older technology for data storage and exchange required each data point to speak the same “language,” with uniform formatting, whether organizations received that data in formats like CSV or Parquet, through variable different exchange interfaces. In “translating” this language over and over, information could get lost. Important details could get swept up in this translation. Additionally, less sophisticated architecture doesn’t allow users to add new data or duplicate it quickly, and complex, dependent processing chains create data latency. Healthcare decisions are time-sensitive, and this murky or unavailable data means fewer insights delivered when they matter most.
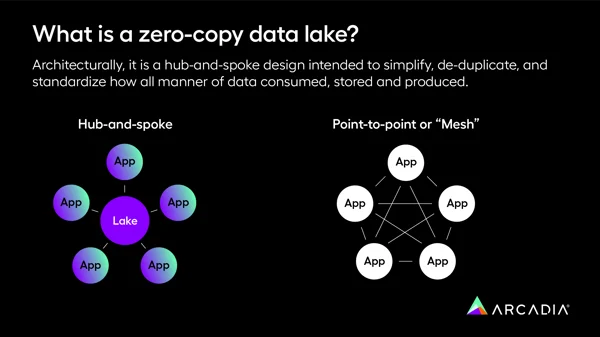
The introduction of a zero-copy data lake is a critical first step to mitigate these challenges. The zero-copy data lake funnels data through a central hub. This restructures data storage, production, and consumption as we know it. Unlike before, when each application had to use a common language, the zero-copy data lake’s central storage model renders faster, more legible insights.
Read on to learn how the zero-copy data lake will revolutionize healthcare, and how its impact will improve the lives and workflows of employees across the healthcare continuum.
The key difference between a point-to-point or mesh data structure and a zero-copy data lake is how it’s organized. Unlike the point-to-point structure, which directly connects all applications so they can communicate directly with each other, the zero-copy data lake offers a hub-and-spoke design. All information flows into a central hub, where it’s centralized, simplified, and standardized.
To get more technical, Arcadia’s zero-copy data store employs specific conventions for using Parquet on top of AWS S3, which enables partition, offset, and versioning capabilities. Put more simply, that means it can distribute data across multiple tables or sites, so that users across an organization can see it. When someone changes or updates a dataset, users in a zero-copy data lake can see when who made the changes (and when), so they’re aware of how data has changed over time.
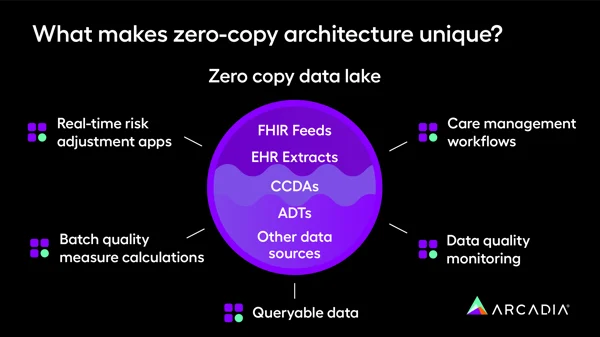
Finally, a zero-copy data lake makes data management and retrieval seamless. When data passes through fewer apps, analysts and platform users can retrieve it faster, in a less adulterated, “purer” form. There are fewer moving parts and less system complexity, so responsiveness increases (while lagging processes get speedier).
1. More efficient feature delivery: By streamlining the communications of apps through this central hub, the zero-copy data lake eliminates negotiating between different data formats, which can be tedious.
2. Discoverability and data consistency: When separate apps don’t have to have a “conversation,” and connectors send data through the central hub of the hub-and-spoke model instead, they’re ready to review more quickly. Users can discover them faster, and there are fewer latency and sync issues. With this centralized storage, there’s one clear source of truth.
3. Ease of schema evolution: If users want to add new information to a data set, the zero-copy data lake makes it seamless, whereas before, it would require coordination between multiple teams. This also makes it more adaptable — now, instead of software changes, new data is available with updated configurations.
4. System simplification: The zero-copy data lake uses fewer components for more stability and responsiveness. In short, it eliminates complication and creates a straightforward data path. Through this, users get a clear route to improved cost and time efficiencies.
The zero-copy data lake offers plenty of bells and whistles, but what’s important is why they matter in healthcare. For users across the care continuum, from providers to data analysts, there are many benefits:
All this equates to improved data management, better access to data, and cost savings. Data managers can maintain high quality data with ease and respond quickly to data issues. IT leaders can empower everyone from care managers to clinicians to analysts to access the data they need with self-service tools. And overhead costs become more manageable for data storage, movement, duplication, processing.
If you’re swimming in data terminology, keep paddling. The zero-copy data lake finds a perfect partner in a data lakehouse, a combination of a data lake and warehouse that offers the best of both worlds.
These two pair well because the zero-copy data lake needs both structure and flexibility, which the lakehouse provides. The lakehouse makes data available at several stages of quality, unstructured to refined. For analysts, this means they can tap this “raw” data for real-time, predictive analytics and actionable insights. When data are so accessible, analysts can jump directly into that central hub and get to work on important projects without lag time.
Healthcare excellence is built on reliable, high-quality data. With the right data infrastructure, organizations can unearth important insights quickly, and act on them just as fast.
Want to stay agile in healthcare’s tumultuous waters? Learn more about how forward-thinking organizations can use the zero-copy data lake and data lakehouse to innovate for healthier, happier lives.